Solving Poisson PDE Systems (https://
with boundary conditions
where
using NeuralPDE
using Lux
using Optimization
using OptimizationOptimJL
using ModelingToolkit
using DomainSets
using LineSearches
using Plots2D PDE
@parameters x y
@variables u(..)
Dxx = Differential(x)^2
Dyy = Differential(y)^2
eq = Dxx(u(x, y)) + Dyy(u(x, y)) ~ -sinpi(x) * sinpi(y)Differential(x, 2)(u(x, y)) + Differential(y, 2)(u(x, y)) ~ -sinpi(x)*sinpi(y)Boundary conditions
bcs = [
u(0, y) ~ 0.0,
u(1, y) ~ 0.0,
u(x, 0) ~ 0.0,
u(x, 1) ~ 0.0
]4-element Vector{Symbolics.Equation}:
u(0, y) ~ 0.0
u(1, y) ~ 0.0
u(x, 0) ~ 0.0
u(x, 1) ~ 0.0Space domains
domains = [
x ∈ DomainSets.Interval(0.0, 1.0),
y ∈ DomainSets.Interval(0.0, 1.0)
]2-element Vector{Symbolics.VarDomainPairing}:
Symbolics.VarDomainPairing(x, 0.0 .. 1.0)
Symbolics.VarDomainPairing(y, 0.0 .. 1.0)Build a neural network for the PDE solver.
Input: 2 dimensions.
Hidden layers: 16 neurons * 2 layers.
Output: single output u(x, y)
dim = 2
chain = Lux.Chain(Dense(dim, 16, Lux.σ), Dense(16, 16, Lux.σ), Dense(16, 1))Chain(
layer_1 = Dense(2 => 16, σ), # 48 parameters
layer_2 = Dense(16 => 16, σ), # 272 parameters
layer_3 = Dense(16 => 1), # 17 parameters
) # Total: 337 parameters,
# plus 0 states.Discretization method usesPhysicsInformedNN() (PINN).
dx = 0.05
discretization = PhysicsInformedNN(chain, QuadratureTraining(; batch = 200, abstol = 1e-6, reltol = 1e-6))NeuralPDE.PhysicsInformedNN{Lux.Chain{@NamedTuple{layer_1::Lux.Dense{typeof(NNlib.σ), Int64, Int64, Nothing, Nothing, Static.True}, layer_2::Lux.Dense{typeof(NNlib.σ), Int64, Int64, Nothing, Nothing, Static.True}, layer_3::Lux.Dense{typeof(identity), Int64, Int64, Nothing, Nothing, Static.True}}, Nothing}, NeuralPDE.QuadratureTraining{Float64, Integrals.CubatureJLh}, Nothing, Nothing, NeuralPDE.Phi{LuxCore.StatefulLuxLayerImpl.StatefulLuxLayer{Val{true}, Lux.Chain{@NamedTuple{layer_1::Lux.Dense{typeof(NNlib.σ), Int64, Int64, Nothing, Nothing, Static.True}, layer_2::Lux.Dense{typeof(NNlib.σ), Int64, Int64, Nothing, Nothing, Static.True}, layer_3::Lux.Dense{typeof(identity), Int64, Int64, Nothing, Nothing, Static.True}}, Nothing}, Nothing, @NamedTuple{layer_1::@NamedTuple{}, layer_2::@NamedTuple{}, layer_3::@NamedTuple{}}}}, typeof(NeuralPDE.numeric_derivative), Bool, Nothing, Nothing, Nothing, Base.RefValue{Int64}, Base.Pairs{Symbol, Union{}, Tuple{}, @NamedTuple{}}}(Lux.Chain{@NamedTuple{layer_1::Lux.Dense{typeof(NNlib.σ), Int64, Int64, Nothing, Nothing, Static.True}, layer_2::Lux.Dense{typeof(NNlib.σ), Int64, Int64, Nothing, Nothing, Static.True}, layer_3::Lux.Dense{typeof(identity), Int64, Int64, Nothing, Nothing, Static.True}}, Nothing}((layer_1 = Dense(2 => 16, σ), layer_2 = Dense(16 => 16, σ), layer_3 = Dense(16 => 1)), nothing), NeuralPDE.QuadratureTraining{Float64, Integrals.CubatureJLh}(Integrals.CubatureJLh(0), 1.0e-6, 1.0e-6, 1000, 200), nothing, nothing, NeuralPDE.Phi{LuxCore.StatefulLuxLayerImpl.StatefulLuxLayer{Val{true}, Lux.Chain{@NamedTuple{layer_1::Lux.Dense{typeof(NNlib.σ), Int64, Int64, Nothing, Nothing, Static.True}, layer_2::Lux.Dense{typeof(NNlib.σ), Int64, Int64, Nothing, Nothing, Static.True}, layer_3::Lux.Dense{typeof(identity), Int64, Int64, Nothing, Nothing, Static.True}}, Nothing}, Nothing, @NamedTuple{layer_1::@NamedTuple{}, layer_2::@NamedTuple{}, layer_3::@NamedTuple{}}}}(LuxCore.StatefulLuxLayerImpl.StatefulLuxLayer{Val{true}, Lux.Chain{@NamedTuple{layer_1::Lux.Dense{typeof(NNlib.σ), Int64, Int64, Nothing, Nothing, Static.True}, layer_2::Lux.Dense{typeof(NNlib.σ), Int64, Int64, Nothing, Nothing, Static.True}, layer_3::Lux.Dense{typeof(identity), Int64, Int64, Nothing, Nothing, Static.True}}, Nothing}, Nothing, @NamedTuple{layer_1::@NamedTuple{}, layer_2::@NamedTuple{}, layer_3::@NamedTuple{}}}(Lux.Chain{@NamedTuple{layer_1::Lux.Dense{typeof(NNlib.σ), Int64, Int64, Nothing, Nothing, Static.True}, layer_2::Lux.Dense{typeof(NNlib.σ), Int64, Int64, Nothing, Nothing, Static.True}, layer_3::Lux.Dense{typeof(identity), Int64, Int64, Nothing, Nothing, Static.True}}, Nothing}((layer_1 = Dense(2 => 16, σ), layer_2 = Dense(16 => 16, σ), layer_3 = Dense(16 => 1)), nothing), nothing, (layer_1 = NamedTuple(), layer_2 = NamedTuple(), layer_3 = NamedTuple()), nothing, Val{true}())), NeuralPDE.numeric_derivative, false, nothing, nothing, nothing, NeuralPDE.LogOptions(50), Base.RefValue{Int64}(1), true, false, Base.Pairs{Symbol, Union{}, Tuple{}, @NamedTuple{}}())Build the PDE system and discretize it.
@named pde_system = PDESystem(eq, bcs, domains, [x, y], [u(x, y)])
prob = discretize(pde_system, discretization)OptimizationProblem. In-place: true
u0: ComponentVector{Float64}(layer_1 = (weight = [0.45447811484336853 -0.6996963620185852; -0.08530238270759583 -0.04946673661470413; … ; 0.10813415795564651 0.554632842540741; -0.881610631942749 1.2073044776916504], bias = [0.3592636287212372, 0.6406066417694092, 0.03762727230787277, 0.11503881216049194, 0.3195371627807617, 0.49707141518592834, 0.06366989761590958, 0.2290496677160263, -0.3633565902709961, 0.345153272151947, -0.09611723572015762, -0.08180931210517883, 0.4440878629684448, -0.40248915553092957, -0.40338411927223206, 0.5839613676071167]), layer_2 = (weight = [-0.0795326977968216 0.34667056798934937 … 0.10594424605369568 -0.19223889708518982; -0.0816771611571312 0.29795995354652405 … -0.05261801928281784 -0.154372438788414; … ; -0.11617346107959747 -0.2453315556049347 … -0.131074458360672 0.42319169640541077; 0.16617903113365173 -0.01804388128221035 … 0.2710403501987457 0.38838428258895874], bias = [0.03948983550071716, 0.20555493235588074, 0.002166926860809326, -0.06249681115150452, -0.19828185439109802, -0.07728597521781921, -0.1831420660018921, -0.10929432511329651, 0.18512195348739624, 0.18701934814453125, -0.2105104923248291, -0.24268165230751038, 0.06531962752342224, -0.11573401093482971, -0.07375237345695496, 0.1740892231464386]), layer_3 = (weight = [-0.10664843767881393 0.23518726229667664 … -0.3512614667415619 -0.24136090278625488], bias = [-0.1528361439704895]))Callback function to record the loss
lossrecord = Float64[]
callback = function (p, l)
push!(lossrecord, l)
return false
end#1 (generic function with 1 method)Solve the problem. It may take a long time.
opt = OptimizationOptimJL.LBFGS(linesearch = LineSearches.BackTracking())
@time res = Optimization.solve(prob, opt, callback = callback, maxiters=1000)1529.663386 seconds (6.12 G allocations: 509.897 GiB, 2.63% gc time, 6.70% compilation time)
retcode: Success
u: ComponentVector{Float64}(layer_1 = (weight = [1.7014312913534853 -1.7546377924753944; -0.2535044449364984 -0.593764126367128; … ; -0.8763901349729963 -0.5039887210098928; -1.8586140789394154 -1.9129270937678398], bias = [-0.764619554388737, 0.6663875188056844, -0.4525604153848089, 1.4850804203699137, 0.9219987234706168, -0.4544068782455448, 1.1738569942646266, -1.3709102395650818, -0.8071349782734288, 0.6175005464605515, 0.6328151880912282, 0.479350818782751, 0.6508148598407191, -0.7261291477191748, 0.5670681361459305, 2.4768429425742844]), layer_2 = (weight = [0.12132075244485989 0.8078826126880051 … 0.03713173046713772 -0.7269775840340071; -0.4974248237881916 -0.4097585399342696 … 0.6632186806847467 0.4750936318935337; … ; -0.4749892968022235 -0.4624465250357013 … -0.33381937444424403 -0.33239367268873193; 0.10079943320406723 -0.12044830261404686 … 0.21857648078989794 0.524470430273004], bias = [0.13887443667155255, 0.4935371517242537, 0.024338672158928758, -0.17690429834828994, 0.1850813829920132, 0.3210905557486377, -0.2795037493715494, -0.23458913952622326, 0.11247636900671415, 0.4016067557020026, -0.6424081837075205, -0.5363346594761683, 0.37076037717417065, 0.279909679877854, -0.2465259566744482, 0.17664026468542265]), layer_3 = (weight = [-0.6723471805937317 -0.1723340158154566 … 0.9162138004107248 0.8130420744205128], bias = [0.8074624107087067]))plot(lossrecord, xlabel="Iters", yscale=:log10, ylabel="Loss", lab=false)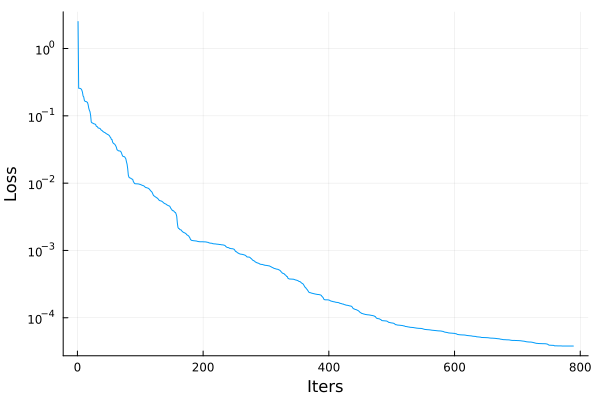
Plot the predicted solution of the PDE and compare it with the analytical solution to see the relative error.
xs, ys = [DomainSets.infimum(d.domain):dx/10:DomainSets.supremum(d.domain) for d in domains]
analytic_sol_func(x,y) = (sinpi(x)*sinpi(y))/(2pi^2)
phi = discretization.phi
u_predict = reshape([first(phi([x, y], res.u)) for x in xs for y in ys], (length(xs), length(ys)))
u_real = reshape([analytic_sol_func(x, y) for x in xs for y in ys], (length(xs), length(ys)))
diff_u = abs.(u_predict .- u_real)201×201 Matrix{Float64}:
7.62757e-5 2.13832e-5 3.19533e-5 … 2.47207e-5 1.92071e-5
9.91268e-5 4.5413e-5 6.78893e-6 2.31577e-7 5.54727e-6
0.000121774 6.92063e-5 1.81076e-5 2.46097e-5 3.067e-5
0.000144201 9.27487e-5 4.27226e-5 4.97767e-5 5.61337e-5
0.000166395 0.000116026 6.70429e-5 7.52431e-5 8.19114e-5
0.00018834 0.000139026 9.10558e-5 … 0.000100983 0.000107976
0.000210024 0.000161735 0.000114749 0.000126971 0.000134302
0.000231434 0.00018414 0.000138111 0.000153182 0.000160863
0.000252557 0.000206231 0.000161131 0.00017959 0.000187633
0.000273381 0.000227995 0.000183798 0.000206172 0.000214587
⋮ ⋱ ⋮
0.00060313 0.000575769 0.000548051 0.00228307 0.00231954
0.000615216 0.000587462 0.000559335 0.00234333 0.00238082
0.000627099 0.000598961 0.000570431 0.00240382 0.00244232
0.000638768 0.000610253 0.000581328 … 0.00246452 0.00250403
0.000650208 0.000621326 0.000592014 0.00252542 0.00256592
0.000661407 0.000632166 0.000602476 0.0025865 0.00262799
0.000672351 0.00064276 0.0006127 0.00264775 0.00269023
0.000683025 0.000653095 0.000622675 0.00270915 0.0027526
0.000693414 0.000663155 0.000632385 … 0.00277068 0.00281509p1 = plot(xs, ys, u_real, linetype=:contourf, title = "analytic");
p2 = plot(xs, ys, u_predict, linetype=:contourf, title = "predicted");
p3 = plot(xs, ys, diff_u, linetype=:contourf, title = "error");
plot(p1, p2, p3)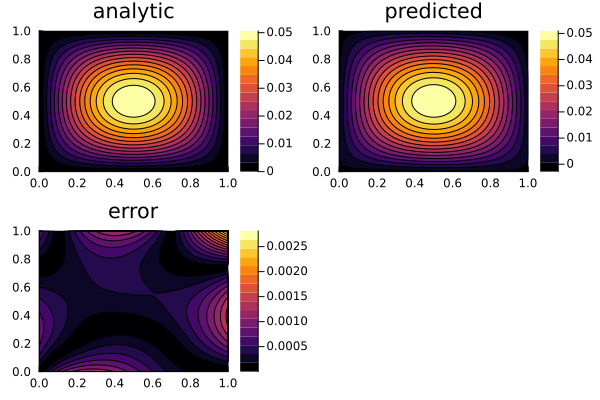
This notebook was generated using Literate.jl.