using NeuralPDE
using Lux
using OptimizationOptimisers
using OrdinaryDiffEq
using LinearAlgebra
using Random
using Plots
rng = Random.Xoshiro(0)Random.Xoshiro(0xdb2fa90498613fdf, 0x48d73dc42d195740, 0x8c49bc52dc8a77ea, 0x1911b814c02405e8, 0x22a21880af5dc689)Solve ODEs¶
The true function:
model(u, p, t) = cospi(2t)model (generic function with 1 method)Prepare data
tspan = (0.0, 1.0)
u0 = 0.0
prob = ODEProblem(model, u0, tspan)ODEProblem with uType Float64 and tType Float64. In-place: false
Non-trivial mass matrix: false
timespan: (0.0, 1.0)
u0: 0.0Construct a neural network to solve the problem.
chain = Lux.Chain(Lux.Dense(1, 5, σ), Lux.Dense(5, 1))
ps, st = Lux.setup(rng, chain) |> f64((layer_1 = (weight = [-0.04929668828845024; -0.3266667425632477; … ; -1.4946011304855347; -1.0391809940338135;;], bias = [-0.458548903465271, -0.8280583620071411, -0.38509929180145264, 0.32322537899017334, -0.32623517513275146]), layer_2 = (weight = [0.565667450428009 -0.6051373481750488 … 0.3129439353942871 0.22128701210021973], bias = [-0.11007555574178696])), (layer_1 = NamedTuple(), layer_2 = NamedTuple()))Solve the ODE as in DifferentialEquations.jl, just change the solver algorithm to NeuralPDE.NNODE().
optimizer = OptimizationOptimisers.Adam(0.1)
alg = NeuralPDE.NNODE(chain, optimizer, init_params = ps)
sol = solve(prob, alg, maxiters=2000, saveat = 0.01)┌ Warning: Mixed-Precision `matmul_cpu_fallback!` detected and Octavian.jl cannot be used for this set of inputs (C [Matrix{Float64}]: A [Base.ReshapedArray{Float32, 2, SubArray{Float32, 1, Vector{Float32}, Tuple{UnitRange{Int64}}, true}, Tuple{}}] x B [Matrix{Float64}]). Converting to common type to to attempt to use BLAS. This may be slow.
└ @ LuxLib.Impl ~/.julia/packages/LuxLib/rMkwk/src/impl/matmul.jl:198
retcode: Success
Interpolation: Trained neural network interpolation
t: 0.0:0.01:1.0
u: 101-element Vector{Float64}:
0.0
0.010749201118431145
0.021243785091922977
0.03146954456391477
0.04141164036773923
0.051054627411539946
0.06038248951440946
0.06937868387373189
0.07802619579072576
0.08630760420856322
⋮
-0.08273961519843215
-0.07417756058487174
-0.06521682422476019
-0.05586996729327343
-0.046149647640710965
-0.036068584995055615
-0.025639528595373873
-0.014875227149738931
-0.0037884010112895494Comparing to the regular solver
sol2 = solve(prob, Tsit5(), saveat=sol.t)retcode: Success
Interpolation: 1st order linear
t: 101-element Vector{Float64}:
0.0
0.01
0.02
0.03
0.04
0.05
0.06
0.07
0.08
0.09
⋮
0.92
0.93
0.94
0.95
0.96
0.97
0.98
0.99
1.0
u: 101-element Vector{Float64}:
0.0
0.009993422791184238
0.019947403330306007
0.02982266232355515
0.03958026253817591
0.049181634380280906
0.058588842486624694
0.06776483889364554
0.07667346491253861
0.08527952991142694
⋮
-0.07667081637919534
-0.06776345741408192
-0.05858914312294849
-0.04918356177418144
-0.03958332717566935
-0.029825978674801627
-0.019949981158467987
-0.00999472505306294
-5.263244789328062e-7plot(sol2, label = "Tsit5")
plot!(sol.t, sol.u, label = "NNODE")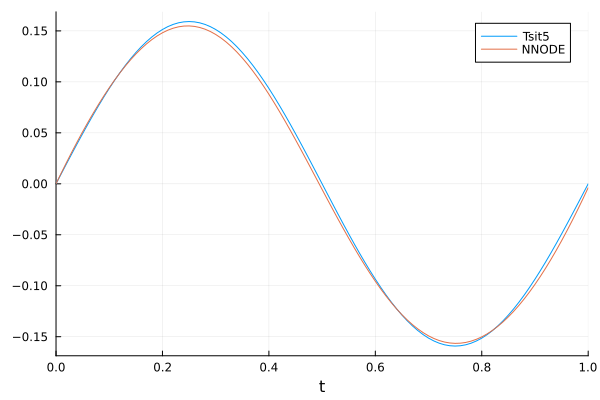
Parameter estimation¶
using NeuralPDE, OrdinaryDiffEq, Lux, Random, OptimizationOptimJL, LineSearches, Plots
rng = Random.Xoshiro(0)Random.Xoshiro(0xdb2fa90498613fdf, 0x48d73dc42d195740, 0x8c49bc52dc8a77ea, 0x1911b814c02405e8, 0x22a21880af5dc689)NNODE only supports out-of-place functions
function lv(u, p, t)
u₁, u₂ = u
α, β, γ, δ = p
du₁ = α * u₁ - β * u₁ * u₂
du₂ = δ * u₁ * u₂ - γ * u₂
[du₁, du₂]
endlv (generic function with 1 method)Generate data
tspan = (0.0, 5.0)
u0 = [5.0, 5.0]
true_p = [1.5, 1.0, 3.0, 1.0]
prob = ODEProblem(lv, u0, tspan, true_p)
sol_data = solve(prob, Tsit5(), saveat = 0.01)
t_ = sol_data.t
u_ = Array(sol_data)2×501 Matrix{Float64}:
5.0 4.82567 4.65308 4.48283 4.31543 … 1.01959 1.03094 1.04248
5.0 5.09656 5.18597 5.26791 5.34212 0.397663 0.389887 0.382307Define a neural network
n = 15
chain = Chain(Dense(1, n, σ), Dense(n, n, σ), Dense(n, n, σ), Dense(n, 2))
ps, st = Lux.setup(rng, chain) |> f64((layer_1 = (weight = [-0.04929668828845024; -0.3266667425632477; … ; -1.3531280755996704; -0.2917589843273163;;], bias = [0.28568029403686523, -0.4209803342819214, -0.24613642692565918, -0.9429000616073608, -0.3618292808532715, 0.077278733253479, 0.9969245195388794, 0.7939795255661011, 0.45440757274627686, -0.4830443859100342, -0.6861011981964111, -0.3221019506454468, -0.5597391128540039, -0.15051674842834473, 0.9440881013870239]), layer_2 = (weight = [-0.08606009185314178 -0.2168799340724945 … -0.3507671356201172 0.07374405860900879; 0.24009406566619873 -0.23728196322917938 … 0.3494441509246826 -0.21207460761070251; … ; 0.3976286053657532 0.28444960713386536 … -0.32817623019218445 0.3963923156261444; -0.07926430553197861 0.35875919461250305 … -0.035931285470724106 -0.2851111590862274], bias = [-0.065037302672863, 0.18384626507759094, 0.17181798815727234, -0.17310386896133423, 0.06428726017475128, 0.09600061178207397, -0.08703552931547165, 0.06890828162431717, -0.16194558143615723, -0.14649711549282074, -0.14649459719657898, -0.04401325806975365, -0.015492657199501991, 0.1046019047498703, 0.15015578269958496]), layer_3 = (weight = [-0.2995997667312622 0.1492127627134323 … -0.011808237992227077 -0.3409591317176819; 0.4351722300052643 0.1286778748035431 … -0.20781199634075165 -0.030425487086176872; … ; -0.02206072397530079 0.1434853971004486 … -0.05763476714491844 -0.2672235369682312; 0.2975636124610901 -0.06781639903783798 … 0.4012162387371063 0.1212344542145729], bias = [0.04135546088218689, -0.2398381233215332, 0.1595604568719864, 0.08355490118265152, -0.06149742379784584, -0.06998120248317719, -0.008059235289692879, -0.10936713218688965, -0.18340998888015747, 0.06297893822193146, 0.04081515222787857, -0.04258332401514053, 0.11171907186508179, -0.21218737959861755, 0.07965957373380661]), layer_4 = (weight = [0.3909372091293335 -0.23473051190376282 … 0.07385867834091187 0.31727132201194763; -0.04396386072039604 0.1817844808101654 … -0.26729491353034973 0.24492914974689484], bias = [0.04966225475072861, -0.04299044609069824])), (layer_1 = NamedTuple(), layer_2 = NamedTuple(), layer_3 = NamedTuple(), layer_4 = NamedTuple()))Loss function
additional_loss(phi, θ) = sum(abs2, phi(t_, θ) .- u_) / size(u_, 2)additional_loss (generic function with 1 method)NNODE solver
opt = LBFGS(linesearch = BackTracking())
alg = NNODE(chain, opt, ps; strategy = WeightedIntervalTraining([0.7, 0.2, 0.1], 500), param_estim = true, additional_loss)NeuralPDE.NNODE{Lux.Chain{@NamedTuple{layer_1::Lux.Dense{typeof(NNlib.σ), Int64, Int64, Nothing, Nothing, Static.True}, layer_2::Lux.Dense{typeof(NNlib.σ), Int64, Int64, Nothing, Nothing, Static.True}, layer_3::Lux.Dense{typeof(NNlib.σ), Int64, Int64, Nothing, Nothing, Static.True}, layer_4::Lux.Dense{typeof(identity), Int64, Int64, Nothing, Nothing, Static.True}}, Nothing}, Optim.LBFGS{Nothing, LineSearches.InitialStatic{Float64}, LineSearches.BackTracking{Float64, Int64}, Returns{Nothing}}, @NamedTuple{layer_1::@NamedTuple{weight::Matrix{Float64}, bias::Vector{Float64}}, layer_2::@NamedTuple{weight::Matrix{Float64}, bias::Vector{Float64}}, layer_3::@NamedTuple{weight::Matrix{Float64}, bias::Vector{Float64}}, layer_4::@NamedTuple{weight::Matrix{Float64}, bias::Vector{Float64}}}, Bool, NeuralPDE.WeightedIntervalTraining{Float64}, Bool, typeof(Main.var"##225".additional_loss), Vector{Any}, Base.Pairs{Symbol, Union{}, Tuple{}, @NamedTuple{}}}(Lux.Chain{@NamedTuple{layer_1::Lux.Dense{typeof(NNlib.σ), Int64, Int64, Nothing, Nothing, Static.True}, layer_2::Lux.Dense{typeof(NNlib.σ), Int64, Int64, Nothing, Nothing, Static.True}, layer_3::Lux.Dense{typeof(NNlib.σ), Int64, Int64, Nothing, Nothing, Static.True}, layer_4::Lux.Dense{typeof(identity), Int64, Int64, Nothing, Nothing, Static.True}}, Nothing}((layer_1 = Dense(1 => 15, σ), layer_2 = Dense(15 => 15, σ), layer_3 = Dense(15 => 15, σ), layer_4 = Dense(15 => 2)), nothing), Optim.LBFGS{Nothing, LineSearches.InitialStatic{Float64}, LineSearches.BackTracking{Float64, Int64}, Returns{Nothing}}(10, LineSearches.InitialStatic{Float64}(1.0, false), LineSearches.BackTracking{Float64, Int64}(0.0001, 0.5, 0.1, 1000, 3, Inf, nothing), nothing, Returns{Nothing}(nothing), Optim.Flat(), true), (layer_1 = (weight = [-0.04929668828845024; -0.3266667425632477; … ; -1.3531280755996704; -0.2917589843273163;;], bias = [0.28568029403686523, -0.4209803342819214, -0.24613642692565918, -0.9429000616073608, -0.3618292808532715, 0.077278733253479, 0.9969245195388794, 0.7939795255661011, 0.45440757274627686, -0.4830443859100342, -0.6861011981964111, -0.3221019506454468, -0.5597391128540039, -0.15051674842834473, 0.9440881013870239]), layer_2 = (weight = [-0.08606009185314178 -0.2168799340724945 … -0.3507671356201172 0.07374405860900879; 0.24009406566619873 -0.23728196322917938 … 0.3494441509246826 -0.21207460761070251; … ; 0.3976286053657532 0.28444960713386536 … -0.32817623019218445 0.3963923156261444; -0.07926430553197861 0.35875919461250305 … -0.035931285470724106 -0.2851111590862274], bias = [-0.065037302672863, 0.18384626507759094, 0.17181798815727234, -0.17310386896133423, 0.06428726017475128, 0.09600061178207397, -0.08703552931547165, 0.06890828162431717, -0.16194558143615723, -0.14649711549282074, -0.14649459719657898, -0.04401325806975365, -0.015492657199501991, 0.1046019047498703, 0.15015578269958496]), layer_3 = (weight = [-0.2995997667312622 0.1492127627134323 … -0.011808237992227077 -0.3409591317176819; 0.4351722300052643 0.1286778748035431 … -0.20781199634075165 -0.030425487086176872; … ; -0.02206072397530079 0.1434853971004486 … -0.05763476714491844 -0.2672235369682312; 0.2975636124610901 -0.06781639903783798 … 0.4012162387371063 0.1212344542145729], bias = [0.04135546088218689, -0.2398381233215332, 0.1595604568719864, 0.08355490118265152, -0.06149742379784584, -0.06998120248317719, -0.008059235289692879, -0.10936713218688965, -0.18340998888015747, 0.06297893822193146, 0.04081515222787857, -0.04258332401514053, 0.11171907186508179, -0.21218737959861755, 0.07965957373380661]), layer_4 = (weight = [0.3909372091293335 -0.23473051190376282 … 0.07385867834091187 0.31727132201194763; -0.04396386072039604 0.1817844808101654 … -0.26729491353034973 0.24492914974689484], bias = [0.04966225475072861, -0.04299044609069824])), false, true, NeuralPDE.WeightedIntervalTraining{Float64}([0.7, 0.2, 0.1], 500), true, Main.var"##225".additional_loss, Any[], false, Base.Pairs{Symbol, Union{}, Tuple{}, @NamedTuple{}}())Solve the problem
Use verbose=true to see the fitting process
sol = solve(prob, alg, verbose = false, abstol = 1e-8, maxiters = 5000, saveat = t_)retcode: Success
Interpolation: Trained neural network interpolation
t: 501-element Vector{Float64}:
0.0
0.01
0.02
0.03
0.04
0.05
0.06
0.07
0.08
0.09
⋮
4.92
4.93
4.94
4.95
4.96
4.97
4.98
4.99
5.0
u: 501-element Vector{Vector{Float64}}:
[5.0, 5.0]
[4.824114636017488, 5.094075716900684]
[4.650763438659717, 5.182090337090541]
[4.480297300998596, 5.263436608912205]
[4.313062541664789, 5.337587391187457]
[4.149391318144409, 5.404114742487141]
[3.9895933657484863, 5.4627018014172215]
[3.8339494038903017, 5.513147056485382]
[3.682706323483366, 5.555361602598729]
[3.5360740844903553, 5.589360718767111]
⋮
[0.9630899976235296, 0.4525509916354862]
[0.9726392934145105, 0.4434173243094186]
[0.9822773140645404, 0.43448866840026046]
[0.9920005066641115, 0.4257587648428727]
[1.0018053174450445, 0.41722150778720923]
[1.011688194245857, 0.40887094191007645]
[1.0216455889574125, 0.4007012597025419]
[1.031673959943653, 0.3927067987378621]
[1.0417697744311605, 0.3848820389248413]See the fitted parameters
println(sol.k.u.p)[1.5012259318680252, 1.0006511220222751, 2.9972359175523073, 0.9987022399353156]
Visualize the fit
plot(sol, labels = ["u1_pinn" "u2_pinn"])
plot!(sol_data, labels = ["u1_data" "u2_data"])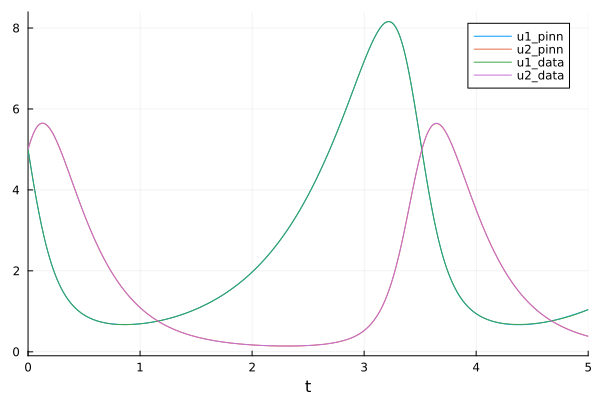
This notebook was generated using Literate.jl.